
Création et vérification de checksums sous Windows avec Hashcheck, DaVinci Resolve et Checksum par Corz.
Présentation de 3 outils de création et vérification de checksums pour 3 utilisations différentes: ingestion de médias depuis disques externes, gestion de dossiers ou fichiers souvent modifiés et envoi de données avec vérification tierce.
Comme toujours, une liste de tous les autres articles de ce blog est disponible ICI.
Introduction
Dans la première partie, j’ai présenté comment je gérais mes différents backups et m’assurait de garder plusieurs copies de mes fichiers de travail pour prévenir toute perte de données. Ainsi, si un de mes disques durs venait à tomber en panne, deux copies existeraient toujours sur des disques indépendants. Mais il existe toujours le risque de corruption de données : qu’arrive-t-il si un secteur du disque devient corrompu et qu’un rush important devient inutilisable ? Qu’un rayon cosmique transforme un « 0 » en « 1 » et change des informations sensibles ? (comme le résultat d’une élection en Belgique en 2003)
Comment s’assurer que les données écrites il y a plusieurs années sont toujours les même aujourd’hui ? C’est là que les checksums deviennent nécessaires pour les contrôler périodiquement et détecter tout changement indésirable.
Selon Wikipedia, un checksum, ou somme de contrôle en français, est : « une courte séquence de données numériques calculée à partir d’un bloc de données plus important (par exemple un fichier ou un message) ». La plupart du temps, cette séquence est une suite de caractères au format hexadécimal appelée « hash ». Plusieurs algorithmes existent et varient en complexité, permettant une résistance plus ou moins grande aux problèmes de collision ( lorsque deux fichiers différents possèdent le même hash et paraissent donc identiques lors de la vérification).
Attention cependant, un checksum n’est utile qu’à partir du moment où il est généré dès l’ingestion de nouveaux médias ou la création de nouveaux fichiers, car on ne peut détecter les changements du fichier que s’ils interviennent entre le moment de création du hash et l’étape de vérification. Ainsi, si l’on créé aujourd’hui le hash d’un fichier de plusieurs années ayant été copié et transféré sur plusieurs supports différents, il n’y aura aucun moyen de savoir si les données sont toujours les même qu’à leur création ou si elles sont déjà corrompues.
De la même manière, un checksum ne peut que détecter un fichier corrompu, mais pas le réparer. C’est pour ça qu’il est aussi nécessaire d’avoir plusieurs copies du même fichier sur différents moyens de stockage pour s’assurer d’avoir un remplacement viable et intact.
Le but ici est donc de pouvoir générer facilement des hashes de fichiers de travail pour s’assurer qu’aucune corruption n’apparaisse, mais aussi de permettre au receveur d’un envoi de fichiers (dans le transfert de rushes par internet par exemple) de vérifier facilement l’intégrité de ce qu’il a reçu.
Je vais donc présenter ici trois solutions qui se complètent dans leur fonctionnalités et leurs utilisations.
Checksums sur Davinci Resolve, outil de clonage
Tout d’abord, je vais présenter l’outil de clonage intégré au logiciel de montage Davinci Resolve.
Il est disponible dans la fenêtre « Media » du logiciel, dans l’onglet « Clone Tool » et permet de cloner des dossiers vers autant de destinations qu’on le souhaite. Il n’est cependant pas possible de sélectionner des fichiers individuels. Plusieurs algorithmes de hashage sont disponibles et le md5 est sélectionné par défaut.

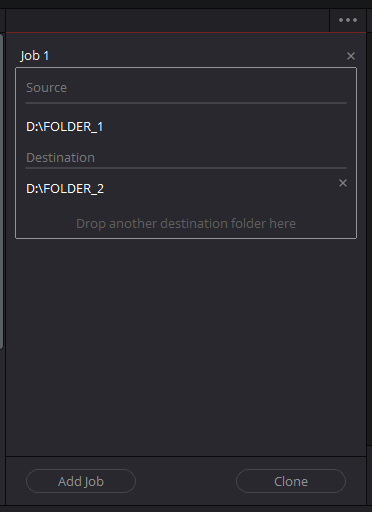
Je préfère utiliser le SHA-512, plus sûr même si plus complexe, car le temps supplémentaire de calcul de la somme de contrôle sera négligeable (plus de détails dans la section « Performances ») par rapport à celui de la lecture et l’écriture de fichiers larges comme des rushes ou vidéos, même sur stockage flash.
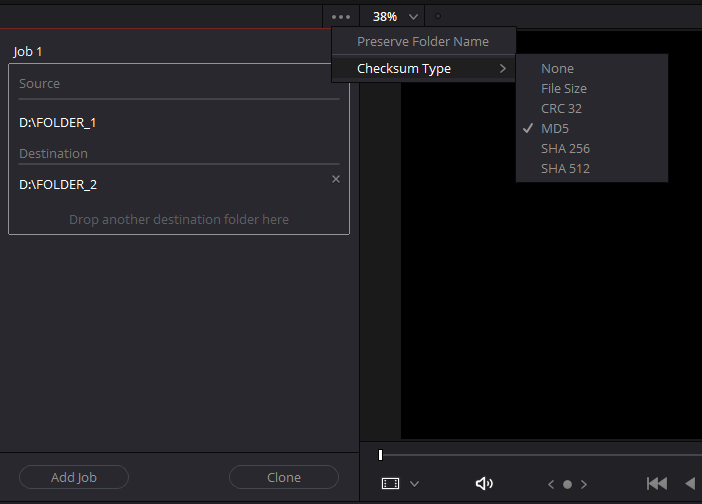
Il faut savoir que cloner des médias avec vérification prendra plus de temps que de copier simplement les fichiers. En effet, plutôt que de simplement lire le fichier source et l’écrire dans la destination, le logiciel va lire le fichier source, générer un checksum (ce qui prends un temps négligeable aujourd’hui), l’écrire dans la destination puis le lire et générer un autre checksum avant de comparer les deux pour vérifier leur correspondance. C’est cette deuxième lecture qui rallonge considérablement le temps total de l’opération.
Cette méthode est donc la plus utile pour ingérer de grosses quantités de médias, par exemple pour copier tous les fichiers d’une carte mémoire ou d’un SSD d’enregistreur externe. Mais l’outil est encore très brut. Il ne peut pas gérer de fichiers individuels et ne fournit aucune information supplémentaire si le clonage échoue. Il sera juste affiché un message « Failed », mais aucun log ne précisera quel fichier est source du problème, il faudra donc recommencer le clonage du début. Je n’ai personnellement eu des erreurs que très rarement, lors de l’utilisation de disques externes douteux par exemple, mais la faute ne revenait pas au logiciel.
Problème aussi, il n’est pas possible de générer seulement les hash et passer la vérification avant de l’opérer plus tard. Dans des situations où il faudrait décharger rapidement des médias, le temps conséquent nécessaire à la vérification peut être prohibitif.
Checksums de fichiers locaux avec Checksum de Corz
J’ai donc cherché un outil bien plus flexible et suis tombé sur le logiciel Checksum sur corz.org (lien du site). C’est un logiciel de gestion intelligente de checksum disposant d’une version gratuite et d’une licence professionnelle très abordable (licence perpétuelle pour 10£ par poste d’installation)
Le logiciel ne créé pas d’icône car on y accède par le menu contextuel. Il suffit de sélectionner le dossier ou fichier pour lequel on veut créer un hash, puis clic>droit : « Create checksums ». L’étape de hashage se lancera automatiquement avec les paramètres par défaut spécifiés dans le fichier checksum.ini. Pour modifier ce fichier: pendant l’opération de hashage, clic-droit dans la fenêtre d’information puis « Edit prefs (Checksum.ini) ». Il sera alors ouvert dans le bloc notes. Tous les réglages sont très bien documentés et expliqués (en anglais), chacun peut donc facilement personnaliser le logiciel à ses besoins.
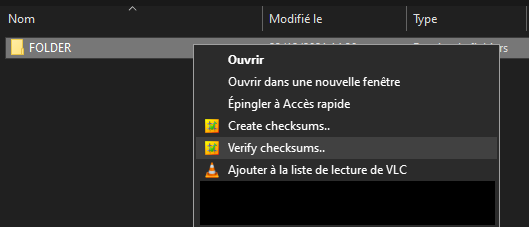

Si l’on veut modifier les réglages au cas par cas, il faut maintenir « Shift » enfoncé au moment de cliquer « Create checksums » ou « Verify checksums » dans le menu contextuel. Une fenêtre s’ouvrira permettant de cocher les réglages nécessaires. Chaque case possède une info-bulle détaillant l’option.
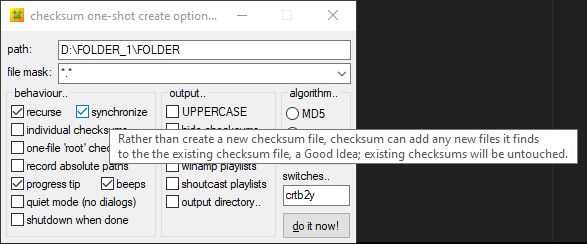
Options de création
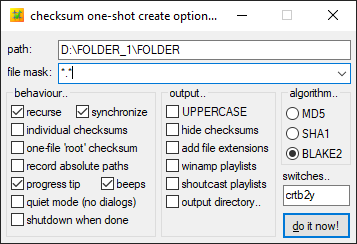
Voici les réglages que j’utilise pour la création :
- Recurse : permet de scanner tous les sous-dossiers du dossier parent. Nécessaire lors du hashage de volumes entiers ou de disques pour ne manquer aucun fichiers.
- Synchronise : le logiciel ne créera pas de nouveau fichier de hashage à chaque scan mais consolidera les nouveaux hashs dans un fichier unique.
- J’utilise le mode par défaut qui créé un fichier .hash par dossier et sous-dossier. Ainsi, si je ne veux vérifier qu’un sous-dossier dans un disque, je n’aurai pas besoin de le scanner entièrement mais seulement la partie concernée.
On peut cependant voir qu’il est possible de créer un fichier .hash séparé pour chaque fichier individuel ou un seul fichier pour l’ensemble des dossiers/sous-dossiers (one-file « root » checksum). - J’utilise l’algorithme Blake2, qui propose un degré de sûreté similaire au SHA-512 tout en étant plus rapide.
Si l’on rehash un dossier dans lequel sont déjà présents des fichiers .hash (par exemple après avoir ajouté de nouveaux fichiers dans un dossier de travail ayant déjà été hashé), le logiciel ne calculera les sommes de contrôle que pour les nouveaux fichiers en passant tout ceux existant déjà, ce qui permet un gain de temps énorme si les dossiers sont volumineux.
Options de vérification
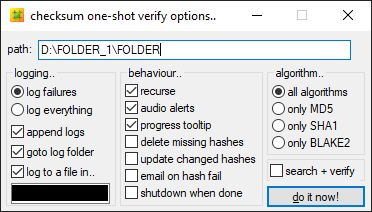
Pour la vérification, voici mes options :
- Recurse : comme pour la création je veux pouvoir vérifier tous les sous-dossiers d’un dossier parent.
Et au cas par cas :
- Delete missing hashes : dans des dossiers de travail, on supprime souvent des fichiers devenu inutiles. Cette option permet donc de supprimer les hash de ces fichiers pour éviter d’avoir des erreurs lors de la vérification.
- Update changed hashes : ce n’est pas une option utile dans le cas de rushes (on ne les modifie pas et l’on souhaite détecter toute modification intempestive). Cependant, si l’on hash des fichiers qui sont régulièrement modifiés, le logiciel comparera la dernière date de modification du fichier avec celle qu’il aura inscrite dans le fichier .hash lors de la création de checksum. Si elle est différente, alors le logiciel en générera une nouvelle pour remplacer celle devenue obsolète. C’est une option à utiliser avec précaution car on ne peut pas savoir quels changements ont été effectués dans le fichier ni par qui.
Observations
Le logiciel Checksum de corz.org est donc extrêmement polyvalent et pratique d’utilisation, permettant en quelques clics de générer des checksums pour des volumes entiers. Si l’on ajoute souvent de nouveaux fichiers, Checksum ne recalculera que les nouvelles sommes, au lieu de hasher le dossier entier à chaque fois. Lors de la vérification, le fait que le logiciel génère un fichier .hash dans chaque dossier et sous dossiers permet de ne vérifier qu’une partie de l’arborescence. Si j’avais à utiliser HashCheck (présenté ci dessous), je devrais soit vérifier le l’arborescence entière à chaque fois, soit créer manuellement un fichier pour chaque dossier et sous-dossier. Mais aucune solution n’est parfaite et voici les points négatifs que j’ai relevé :
- Tout d’abord le logiciel est assez âgé, n’ayant pas été mis à jour depuis 2016. Je ne suis pas sur de sa compatibilité avec Windows 11 même si à priori il ne devrait pas y avoir de problèmes.
- Il n’y a pas beaucoup d’options de hashage, seulement trois algorithmes, dont 2 sont obsolescents (md5 et SHA1) alors que le blake2 n’est que rarement utilisé comparé au SHA-256 et SHA-512.
Cela limite donc son utilisation dans le cas d’envoi de données vers une autre machine, à moins que celle-ci ait aussi le logiciel d’installé pour interpréter les fichiers .hash ou les hashes blake2. - Le logiciel n’utilisera qu’un seul thread en hashage et vérification et sera donc limité à la performance single core du processeur, 585Mo/s en hashage dans mon cas (plus de détails dans la section Performances). Le seul moyen d’atteindre la vitesse maximale de lecture d’un SSD M.2 sera d’utiliser un autre logiciel, turboSFV avec les algorithmes de la famille blake3 qui peuvent utiliser plusieurs coeurs (disponible depuis la mise à jour v9.2 de Décembre 2021). Dans cette configuration, j’ai pu atteindre 3,8Go/s en hashage en utilisant 8 coeurs.
Sur turboSFV par contre, je n’ai pas trouvé d’option permettant de ne recalculer que les hashes des fichiers n’en ayant pas encore. Le logiciel générera donc à chaque fois du nouveaux hashes pour tous les fichiers du dossier cible. Le logiciel ne dispose pas non plus de version gratuite contrairement à Checksum.
Création de checksums pour envoi de données avec HashCheck
L’outil clonage de Resolve est très limité comme nous l’avons vu, et Checksum de Corz utilise un algorithme peu usité. Si l’on souhaite envoyer des données à un destinataire, il y a de fortes chances qu’il ne puisse pas vérifier les sommes Blake2, contrairement à des formats plus populaires comme le SHA-512. Mais voici une alternative pour cette utilisation :
HashCheck est le dernier programme présenté, permettant d’ajouter un onglet « Hashages » dans la fenêtre « Propriétés » de Windows pour tout document ou dossier. Il est disponible à cette adresse: lien du site. Il permet d’utiliser les algorithmes les plus courants, comme le CRC32, MD5, SHA-256 et SHA-512.
Dès l’ouverture de l’onglet, la génération de hashes commencera automatiquement suivant les paramètres choisis. À la fin, il suffira d’enregistrer le fichier dans le dossier de son choix. Attention cependant, si le fichier des hashes est déplacé, la vérification ne marchera plus car le chemin indiqué des fichiers est relatif !
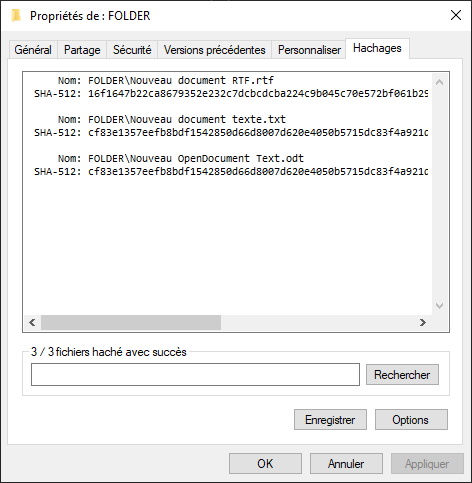
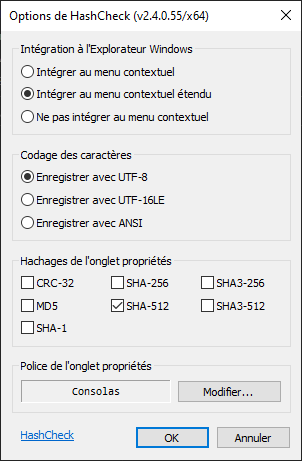
Pour vérifier le dossier, il suffit de double-cliquer sur le fichier de hashes correspondant et l’opération se lancera. A noter que cette opération est multithread et permet donc de saturer en lecture des disques très rapides comme des SSD PCIe (plus d’informations dans la section Performances ci-dessous).
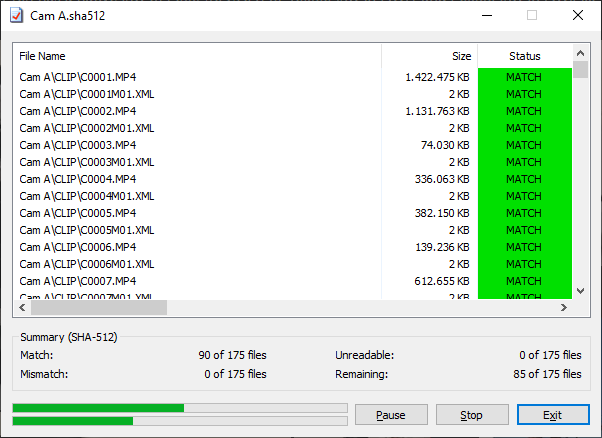
Le logiciel est très simple d’utilisation mais ne permet pas une gestion aussi intelligente des dossiers et sous dossiers que Checksum. Ce n’est pas gênant lors de l’envoi de données car il s’agit souvent d’envoyer un unique dossier contenant tous les fichiers nécessaires. Hashcheck permettra donc de créer un fichier hash unique pour ce dossier, que le destinataire pourra vérifier directement à réception.
Performances
Présentation des problèmes liés au cache
J’ai d’abord effectué des tests de vitesse sur mon ordinateur portable équipé d’un processeur Intel 7700hq, possédant 4 coeurs et 8 threads, avec une fréquence de base de 3,4Ghz et un boost maximum de 3,8GHz. Les tests ont été effectués sur le SSD SATA interne de 256Gb (étant aussi disque système) et sur un HDD 7200 rpm interne de 1To. Le dossier à hasher faisait 52Go environ et était composés de différents rushes.
J’ai rapidement repéré des incohérences dans les résultats, comme des irrégularités sur les vitesses de lecture sans que le processeur ne soit saturé.
J’ai donc réitérés les tests sur mon ordinateur de travail, une tour que j’ai monté et équipée d’un Ryzen 5900X (12 coeurs et 24 threads), boostant à 4,9Ghz single core. Le dossier était cette fois de 44Go. Les disques de tests sont des disques dédiés au stockage de rushes, et n’ont aucune application ou fichier système. Le premier est un SSD SATA de 4To, le second un SSD M.2 PCIe Gen 3 de 1To.
J’ai encore remarqué des problèmes et pense en avoir identifié la cause : les SSDs de qualité sont équipés d’une forme de cache leur permettant de charger plus rapidement des données récemment ou couramment utilisées. Lorsque j’ai effectué le premier test de vitesse avec Checksum sur le dossier test (qui n’avait pas été lu depuis longtemps), la vitesse moyenne a plafonné à seulement 320Mo/s et a pris 2m33s, avec des périodes alternantes de quelques secondes où le disque n’atteignait que 80Mo/s avant de remonter à 470Mo/s. Deuxième test à la suite, dans des conditions identiques sur le même dossier, le test n’aura pris que 1m13s ! HWinfo64 n’a pas pu me donner de vitesse moyenne (affichage a 0 Mo/s tout le long du test), car la mémoire flash n’est à mon avis pas lue mais seulement les données qui ont été chargées dans le cache du disque. Le SSD fait 4To, le cache est donc assez grand pour charger le dossier entier de 44Go dans le cache. Dans le cas du test sur ordinateur portable, je n’ai aucune idée de sa taille ni de son utilisation (vu que le disque est aussi l’hôte du système d’exploitation). Il est possible que le disque n’ai pu charger d’une portion des données du test sur le cache, faisant chuter la vitesse lorsqu’il est plein et que le disque se mette à lire directement la mémoire flash.
Tout ça pour dire que les données de l’ordinateur portable présentées ci-dessous sont à prendre avec un grain de sel. Chaque configuration est différente et demande de tester au cas par cas pour s’assurer du fonctionnement correct, les résultats partagés ici ne peuvent donc pas être extrapolés à chaque cas de figure.
Performances sur ordinateur portable (i7-7700HQ)
Intel 7700hq 4c/8t, 3,4GHz boost all core, 3,8Ghz boost single core.
16Go RAM DDR4 Dual channel 2400Mhz CL17
Dossier de 52Go de rushes divers.
Checksum de Corz, algorithme Blake2
| Tâche | Vitesse moyenne – temps | Élément limitant | Notes |
| Hashage HDD 7200 rpm |
145 Mo/s – 6m33s ( 95 % utilisation ) |
Vitesse lecture disque | |
| Hashage SSD Sata | 370 Mo/s – 2m30s ( 80 et 99 % d’utilisation ) |
Processeur | Résultat incertain (données en cache ou non) |
| Vérification HDD | 146Mo/s – 6m25s ( 95 % utilisation ) |
Vitesse lecture disque | |
| Vérification SSD | 370 Mo/s – 2m32s ( 80 et 99 % d’utilisation ) |
Processeur | Résultat incertain (données en cache ou non) |
HashCheck, algorithme SHA-512
| Tâche | Vitesse moyenne – temps | Élément limitant | Notes |
| Hashage HDD 7200 rpm |
145 Mo/s – 6m33s ( 95 % utilisation ) |
Vitesse lecture disque | |
| Hashage SSD Sata | 302 Mo/s – 3m04s ( 60 % d’utilisation ) |
Processeur | Résultat incertain (données en cache ou non) |
| Vérification HDD | 146Mo/s – 6m25s ( 95 % utilisation ) |
Vitesse lecture disque | |
| Vérification SSD | 515 Mo/s – 1m42s ( 100 % d’utilisation ) |
Vitesse lecture disque | Tâche multithread |
HashCheck, algorithme SHA-256
| Tâche | Vitesse moyenne – temps | Élément limitant | Notes |
| Hashage SSD Sata | 208Mo/s – 4m53s (40 % utilisation) |
Processeur |
Performances sur PC de bureau (Ryzen 9 5900x)
Ryzen 5900x 12c/24t 4,2GHz boost all core, 4,9Ghz boost single core.
64Go RAM DDR4 Dual channel 3600Mhz CL16
Dossier de 44Go de rushes divers.
Checksum de Corz, algorithme Blake2
| Tâche | Vitesse moyenne – temps | Élément limitant | Notes |
| Hashage SSD (SATA) |
585 Mo/s – 1m11s ( 0 % utilisation ) |
Processeur (1c/1t à 100%) |
Données en cache |
| Hashage SSD (SATA) |
320 Mo/s – 2m39s ( 100 % utilisation ) |
Vitesse lecture disque | Données non cachées |
| Hashage SSD (M.2 PCIe Gen 3) |
585 Mo/s – 1m11s ( 25 % d’utilisation ) |
Processeur (1c/1t à 100%) |
|
| Vérification SSD (SATA) |
585 Mo/s – 1m11s ( 0 % utilisation ) |
Processeur (1c/1t à 100%) |
Données en cache |
| Vérification SSD (M.2 PCIe Gen 3) |
585 Mo/s – 1m11s ( 95 % d’utilisation ) |
Processeur (1c/1t à 100%) |
HashCheck, algorithme SHA-512
| Tâche | Vitesse moyenne – temps | Élément limitant | Notes |
| Hashage SSD (SATA) |
500 Mo/s – 1m36s ( 0 % utilisation ) |
Processeur (1c/1t à 100%) |
Données en cache |
| Hashage SSD (M.2 PCIe Gen 3) |
500 Mo/s – 1m36s ( 21 % d’utilisation ) |
Processeur (1c/1t à 100%) |
|
| Vérification SSD (SATA) |
4,4Go/s – 0m10s ( 0 % utilisation) |
Processeur (100 % all core) |
??? – Données en cache | Tâche multithread |
| Vérification SSD (M.2 PCIe Gen 3) |
2,4 Go/s – 0m18s ( 100 % d’utilisation ) |
Vitesse lecture disque | Données non cachées | Tâche multithread |
| Vérification SSD (M.2 PCIe Gen 3) |
3,8 Go/s – 0m12s ( 100 % d’utilisation ) |
Vitesse lecture disque | Données en cache | Tâche multithread |
TurboSFV, algorithme Blake3_2048
| Tâche | Vitesse moyenne – temps | Élément limitant | Notes |
| Hashage SSD (M.2 PCIe Gen 3) |
3,8Go/s – 0m12s ( 100 % utilisation ) |
Vitesse lecture disque | Données en cache | Tâche multithread |
| Hashage SSD (M.2 PCIe Gen 3) |
2,1Go/s – 0m21s ( 100 % utilisation ) |
Vitesse lecture disque | Données non cachées | Tâche multithread |
| Vérification SSD (M.2 PCIe Gen 3) |
3,8 Go/s – 0m12s ( 100 % d’utilisation ) |
Vitesse lecture disque | Données en cache | Tâche multithread |
Observations
On peut conclure de ces tests :
- Sur l’i7 7700hq, la limite de hashage du processeur en Blake2 est d’environ 370Mo/s contre 300Mo/s pour le SHA-512. Le SHA-256, moins adapté aux architectures x64 ne permet d’atteindre que 208Mo/s.
- Sur le Ryzen 5900x, la limite de hashage du processeur en Blake2 est d’environ 585Mo/s contre 500Mo/s pour le SHA-512, l’algorithme blake2 est environ 20 % plus rapide que le SHA-512 dans des conditions similaires.
- L’algorithme choisi n’aura pas d’importance sur le temps de hashage pour tout disque dur, leur vitesse de lecture étant toujours l’élément limitant même sur un processeur relativement vieux comme l’intel i7-7700HQ.
- Checksum de Corz ne possède aucun mode multithread. S’il faut régulièrement vérifier un large volume de données stockées sur SSD relié par PCIe, Hashcheck sera plus rapide pouvant saturer en lecture le disque en utilisant plusieurs cœurs du processeurs. S’il faut aussi générer rapidement des hashes, seul TurboSFV peut saturer un SSD PCIe avec l’utilisation du Blake3, étant l’unique algorithme multithread disponible.
Dans mon utilisation, Checksum reste parfaitement adapté car tous mes moyens de stockages de rushes sont reliés par SATA et sont donc limités à 600Mo/s, très proche des vitesses de hashages observées sur le logiciel. Ces vitesses testées sont aussi les maximums possibles, mais dans une utilisation réelle où les données ne seront sûrement pas en cache, les vitesses seront largement en dessous des limites de hashage du Ryzen 5900x et ne bénéficieraient en rien d’un fonctionnement multithread. - Les caches des disques créent des irrégularités dans les performances et il faut se méfier de leur impact. Dans mon cas par exemple, la vitesse de lecture est divisée par deux lorsqu’il n’est pas disponible.
- Le cas de la vérification sur SSD SATA par HashCheck est incompréhensible. J’ai réitéré la vérification plusieurs fois avec toujours le même résultat. Une vitesse de 4,4 Go/s de lecture alors que le SATA ne permet que 600Mo/s. Les données n’étaient pas chargées dans la RAM (10Go utilisé sur 64Go, alors que le dossier à vérifier fait 44Go) et aucun autre disque n’était utilisé. Je n’ai aucune idée de ce qui a permit ce résultat.
Conclusion
Ce qui devait d’être une simple présentation de logiciels est devenu beaucoup plus complexe en constatant les disparités de performances sur différentes types de disques. Il faut donc bien tester ces programmes dans ses propres conditions et sur le matériel cible et ne pas juste se fier aux chiffres présentés ici. Il est très dur de trouver des informations sur la taille des caches des disques ou sur les performances des microcontrôleurs dans la gestion des données. De plus, chaque fabricant possède ses propres algorithmes, des disques d’apparences similaires pourraient avoir des performances bien disparates surtout lors de l’écriture/lecture de très gros volume de données.
J’espère que ces deux articles auront été utiles et qu’ils introduisent bien aux enjeux et problèmes soulevés sur la gestion et la vérification de l’intégrité des données.